
Transient Bottlenecks in Distributed Systems
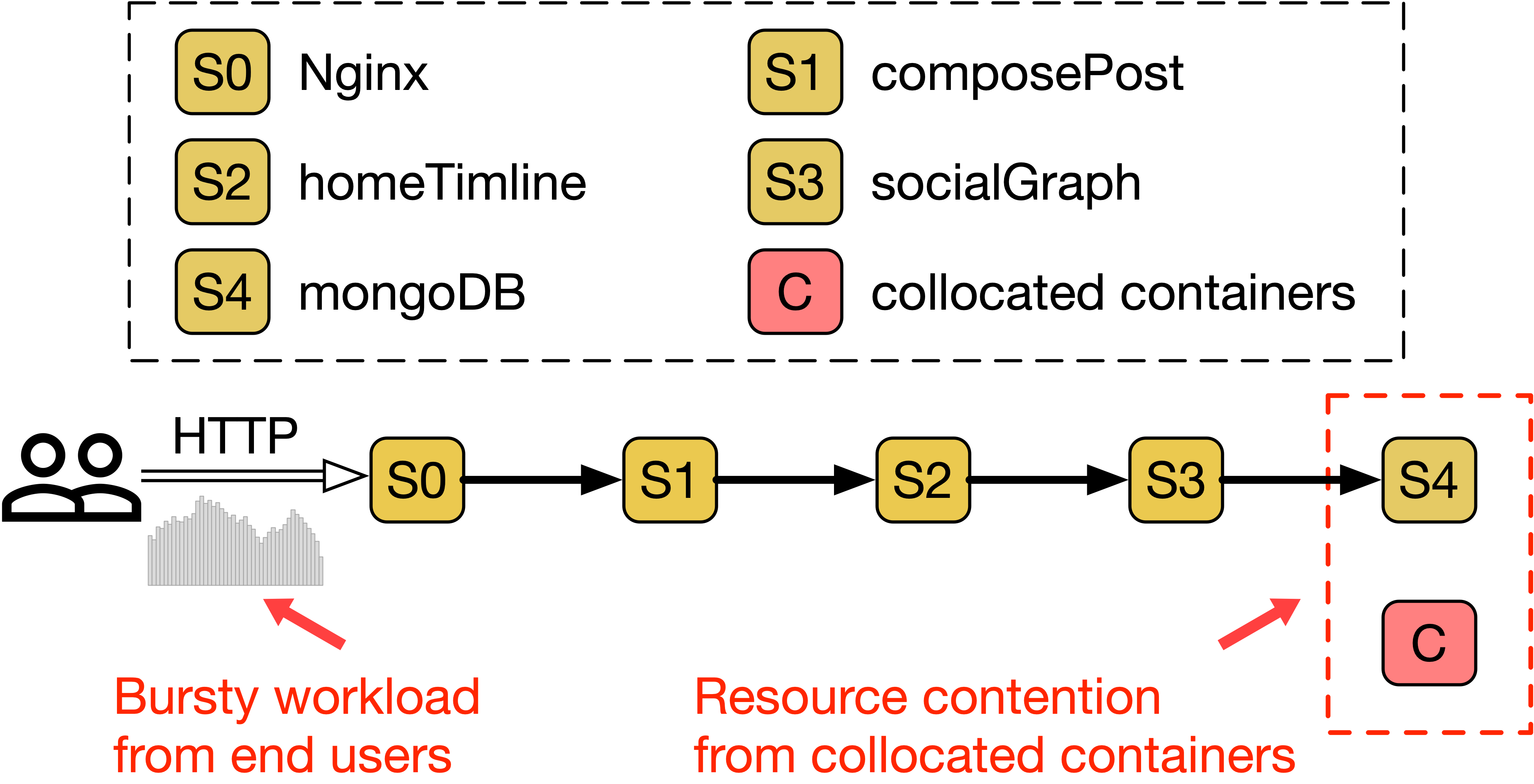
Figure 1. A representative long call chain in microservices application SocialNetwork. Suddenly increased workload or resource contention are comment factors that cause transient bottlenecks.
Maintaining consistently low response times is crucial for mission-critical, web-facing applications (e.g., e-commerce), which are typically implemented using distributed systems such as microservices architectures. Through extensive benchmarking of a microservices application in a cloud environment, we find that response time stability is fragile, exhibiting significant variations ranging from milliseconds to seconds.
Our detailed timeline analysis identifies that even a millibottleneck (a bottleneck lasting sub-seconds) can trigger a queuing effect from a downstream service that propagates to upstream services, resulting in dropped requests and TCP retransmissions lasting several seconds at the weakest link in the chain.
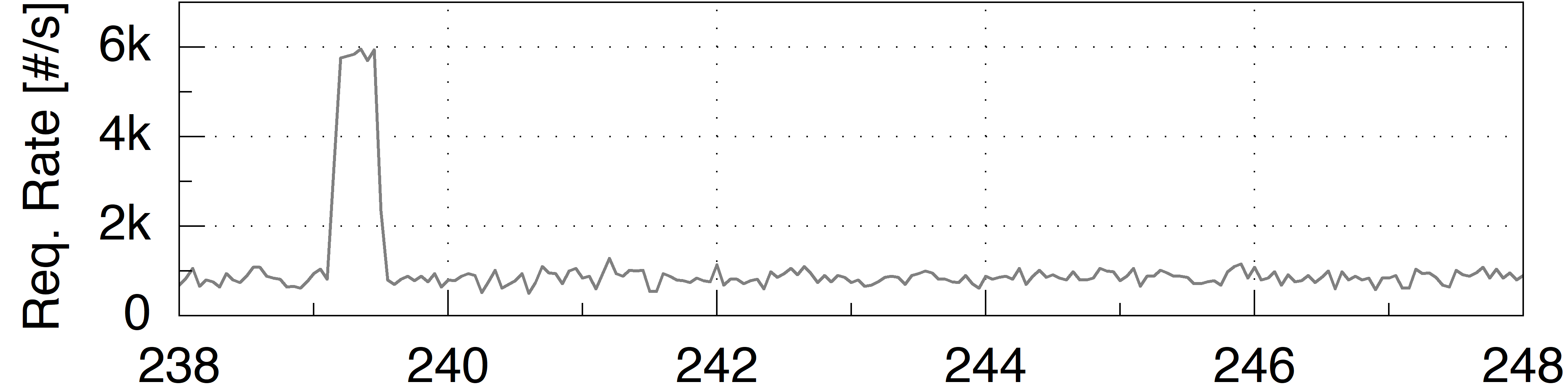
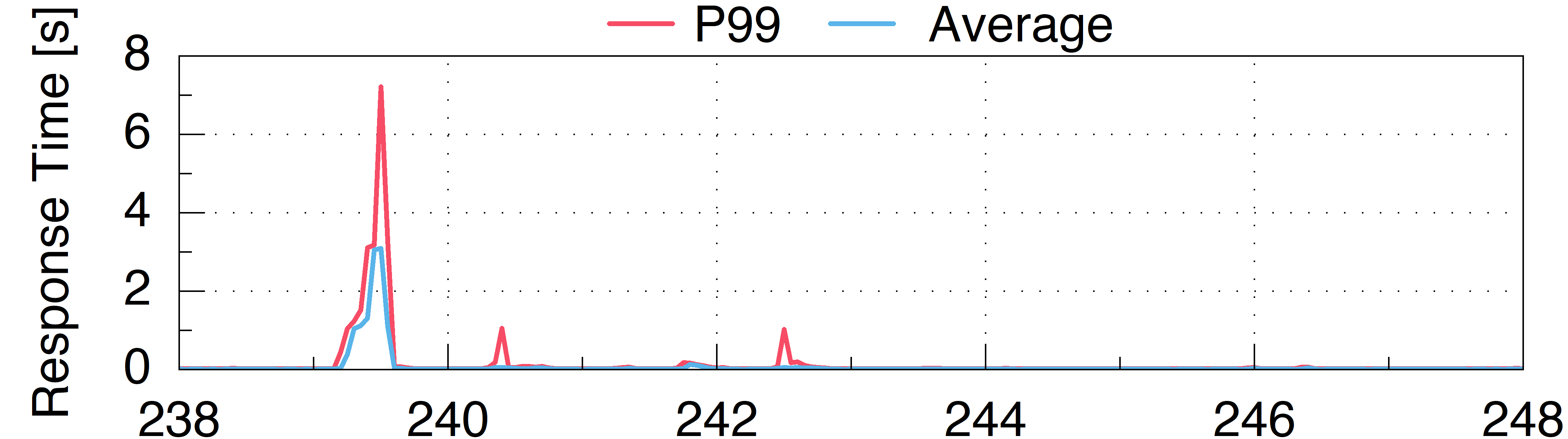
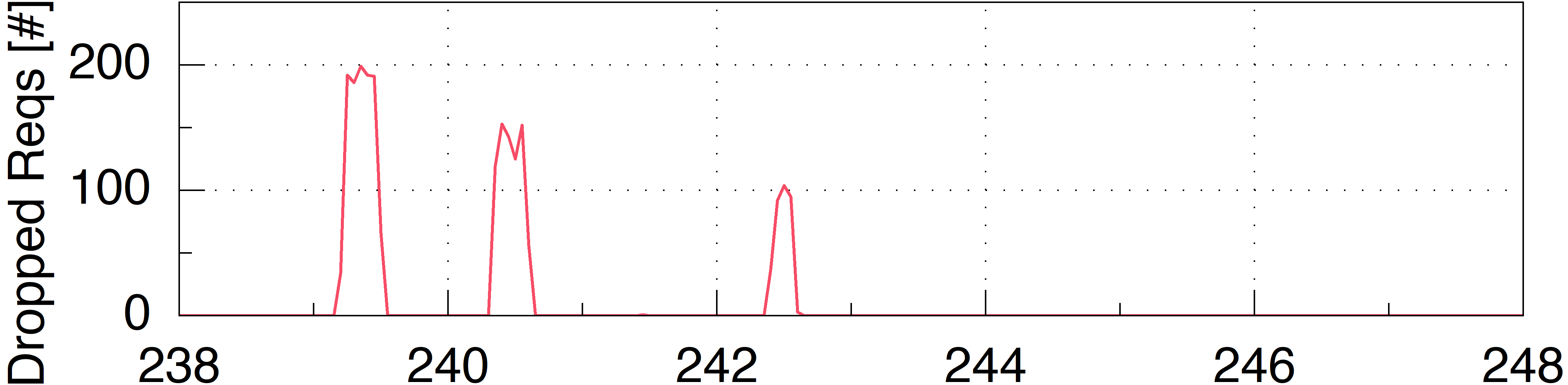
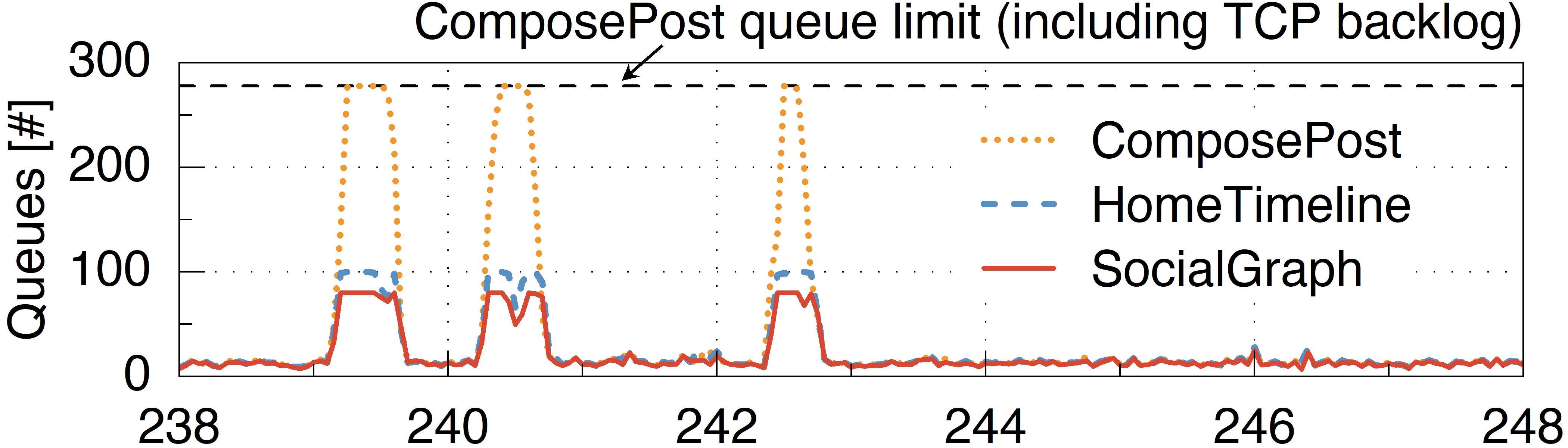
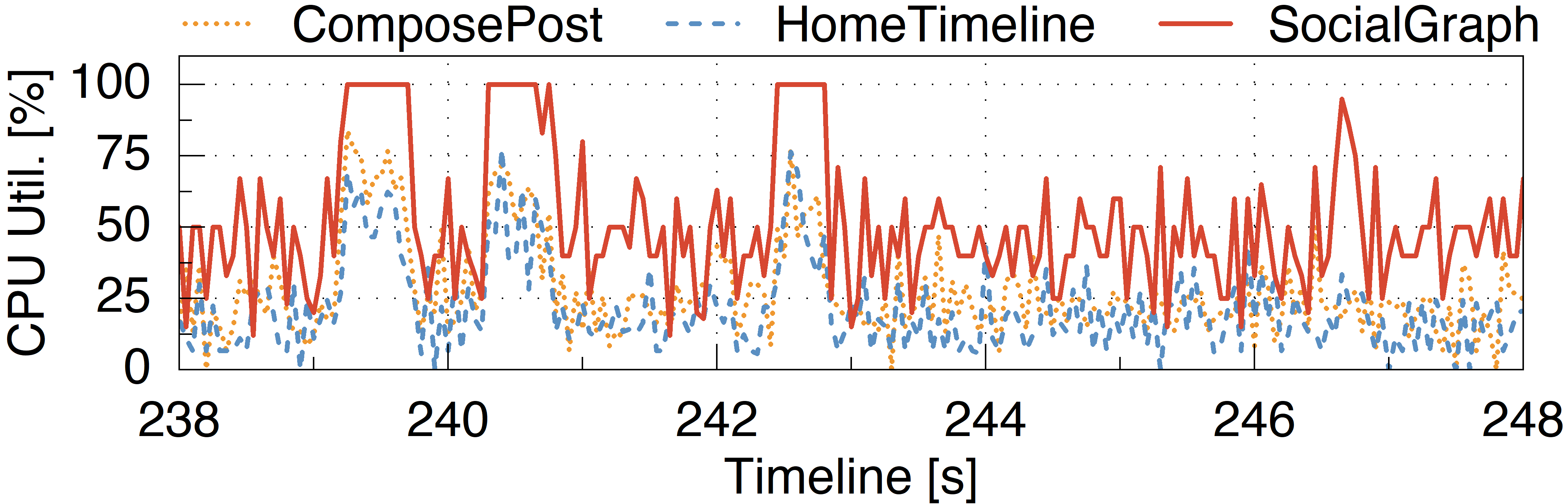
Figure 2. An illustration showing how a single traffic burst triggers multiple waves of dropped requests and TCP retransmissions over a ten-second span, leading to significant response time fluctuations..
External bursty workloads occur when a microservice receives a sudden increase in requests, causing the system to become temporarily overloaded and response times to spike.
Here we show a representative 10-second snapshot, capturing each metric with fine-grained monitors using a 50ms time window. This figure demonstrates how a bursty workload induces substantial response time fluctuations. Notably, even very short resource saturation in a deep downstream microservice can significantly degrade performance, highlighting the critical impact of transient bottlenecks on system stability.
Xuhang Gu
Ph.D. student in Computer Science at Louisiana State University, Baton Rouge, LA.